A big-picture look at how Nvidia got to Turing, and how the new architecture signals an inflection point in GPU evolution.
At Siggraph in August, Nvidia pulled the covers off of Turing, which one could argue is both a successor to not one but both of its preceding generations, Pascal and Volta. In the process, Nvidia confirmed several of the more expected advancements in its next flagship GPU. But it also revealed a few surprises, representing an aggressive-but-justified departure from past generations’ decisions in how the company formulates and rolls out new GPU parts.
Turing marks an important inflection point for Nvidia, as the once disparate markets of 3D graphics and GPU compute overlap enabling Nvidia to focus its priorities. With Turing, Nvidia confirms its conclusion that machine learning is part of the visualization toolkit.
Volta and Turing represent another shift in Nvidia’s evolving GPU development strategy
Let’s step back a bit and consider how the product, architecture, and technology decisions for Nvidia’s GPUs began changing around a decade ago. Until then, the decision was fairly straight-forward for architects, engineers, and product marketers alike. How did spending transistors—to design in a new feature or boost performance of an existing one—translate into a better 3D graphics experience for games (primarily) and professional applications (secondarily)? If it delivered good bang-for-the-buck (“buck” translating to die area and/or watts), it should go in. If not, it should probably wait.
It’s been a while since Nvidia shaped new GPU architectures and technology strictly for the benefit of 3D graphics. Over the last decade, Nvidia’s GPUs have pushed well beyond that core space and into compute-acceleration, autonomous vehicles, robotics, supercomputing and now, front-and-center, machine learning. What began innocently enough as a grassroot initiative in the late 00’s from academics looking to harness the GPU’s superior aptitude for highly parallel, floating-point intensive math has turned the GPU into far more than a graphics engine and Nvidia into far more than a graphics company. The advent of non-graphics, general purpose GPU computing (GPGPU) began influencing the make-up of GPU architectures, an influence compounded by the much more recent development of GPU-accelerated machine learning.
Graphics versus compute: making choices
While these disparate markets and applications certainly do share the same affinity for highly parallel floating point computation, the algorithms employed aren’t the same. And to optimally support the processing both graphics-oriented applications and compute applications means prioritizing different features. Now faced with serving different algorithms and applications with the same GPUs, Nvidia’s development teams had to choose tradeoffs of features and cost.
And choices must be made. The GPU has become anything but a frugal consumer of silicon, and throwing big-ticket items into a chip that might already be maxed out (bound by reticle limits or at least by rational yield goals) adds cost (and possibly watts) for no benefit.
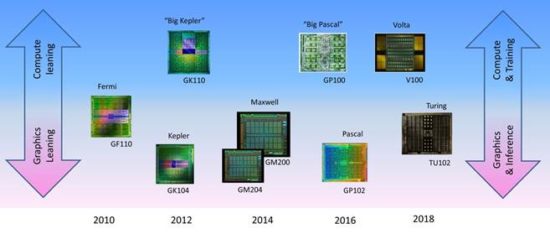
Nvidia learned that lesson with 2010’s Fermi, which was designed with a universal architecture to serve both compute and graphics with the same chips.
Fermi was an ambitious step forward in GPU computing and is a worthy achievement in chip engineering, but the kitchen-sink approach used in its development resulted in a product that was not optimal for all applications, specifically graphics. It hit solid performance levels for 3D graphics, but it fell short in expectations in price/performance and performance/watt metrics. Nvidia took note, and next generation Kepler (2012) adopted a different strategy.
With Kepler, Nvidia for the first time delivered two distinct flavors: what I (not Nvidia) call “graphics-first” versions (starting with GK104) and heftier, “compute-first” versions (starting with the “Big Kepler” GK110 and culminating with the GK210). Compute-first chips weren’t necessarily exclusively used in compute products (e.g., Tesla brand) and similarly, graphics-first chips weren’t only built into graphics products (e.g., GeForce and Quadro brands). Still, with Kepler, there was a clear change from the all-in-one Fermi approach to one pursuing two threads of products from the same GPU generation: one slanted toward compute and datacenters and the other slanted toward for bread-and-butter gaming and professional visual applications.
Nvidia’s next design, Maxwell, proved a bit of an anomaly. Overriding the pursuit of the optimal graphics/compute balance came a different imperative: maximizing performance per watt. At that time, Nvidia was hot on mobile opportunities, notably for automotive and mobile gaming applications (e.g., Shield) but also still likely toying with the prospects of tablets and possibly still phones. With Maxwell, Nvidia actually led with mobile GPU parts, later delivering higher performance parts for desktop applications. A “Big Maxwell” did appear in the form of the GM200 chip, it didn’t take on the big-cost compute-only features like fast FP64. It served more as a maxed-out graphics chip.
With 2016’s Pascal, Nvidia returned to a dual-pronged GPU strategy: one prong leaning toward compute and the other toward graphics, with both leveraging the same core architecture. Out first was “Big Pascal” GP100 bringing back fast FP64 and other features that gave it a very clear compute-first positioning. The bifurcation of GPU products supporting compute versus graphics was pronounced, setting the stage—and speculation—for what the next generation, Volta, would bring.
Volta and Turing: a unifying inflection point in the future of GPU design
Things started to look different again with Volta. 2017’s first Volta chip, the V100, certainly seemed to fit the established pattern: a big-time, no-holds-barred attack on compute-oriented applications. Nvidia gave “Big Volta” hefty FP64 support and seemed to veer away from graphics. Nvidia designed in features that very deliberately focused on machine learning, a sub-space that has significantly caught Nvidia’s interest, if not that of the entire computing industry. Nvidia designed in dedicated Tensor Cores, useful in accelerating both training (the learning) and inference (the application of the learning for “judgment”) applications.
While the make-up of Big Volta made sense given Nvidia’s aggressive push into machine learning, it led to the obvious speculation on what a graphics-focused Volta might end up looking like. What would Nvidia eliminate or trim from the flagship V100 chip? Would Tensor Cores remain or get the boot like high-performance FP64 did in past generations? The Quadro GV100 add-in card GPU was the tip-off. It leveraged the full-blown V100 chip and was packaged in a $9K product. Obviously, this wasn’t the version of Volta that Nvidia would rely on to drive into more mainstream gaming and workstation focused graphical markets. But the Quadro GV100 did show off RTX, software technology that harnessed Volta’s AI features, especially Tensor Cores, to serve a new confluence of machine learning and graphics: AI-accelerated ray tracing.
Nvidia’s new darling market, machine learning, is finding compelling applications in virtually every corner of the computing landscape, including its core gaming and workstation applications. For the latter, consider the work being done to find optimal designs for products being 3D printed. AI can be used to take into account the printing materials to create the optimal structure to balance weight, materials and strength. Or digging deeper into CAD workflows, AI is and will be taking on some of the burden in designing the form and function of the object itself, something Autodesk and Solidworks are talking about. The ability of AI more quickly and effectively analyze 2D, 3D and even 4D (3D + time) imagery has obvious and compelling value in geoscience, surveillance, and medical applications.
But now we can add a 3D rendering application to that list of AI-assisted application. And we’re not talking just any 3D rendering application, but the 3D rendering application: ray tracing, the holy-grail method of producing photorealistic images preferred by virtually every creator and consumer of synthetic 3D imagery, including game developers, film studios, architects, advertisers and industrial designers alike. The Quadro GV100’s claim to fame was not its economical price—far from it at $9,000—it was the GPU’s ability to ray trace complex scenes with credible level of detail at realtime speeds. Moreover, the AI in RTX technology was every bit as instrumental in giving the GV100 realtime status as any of the usual semiconductor-driven advancements like transistor density and switching frequencies.
The RTX software exploiting Volta’s new Tensor Core hardware incorporated a deep learning neural network (DNN) in the ray tracer to accelerate image “convergence” by decreasing the computational load in the latter stages of rendering. Once the image congeals into something it can recognize, AI fills in remaining rays/pixels, de-noising the image and wrapping up the time-consuming rendering process far faster than requiring the full per-ray processing.

The V100 chip demonstrated that, unlike some compute-specific features like FP64, features accelerating machine learning didn’t have to be looked at as a cost-negative for a graphics product. The V100 turned out be a critical linchpin in finally closing the realtime performance gap for ray tracing. And that all leads up to the graphics-focused follow-on of 2018: Turing.
Nvidia’s Turing GPU: a Volta foundation optimized for visual processing
Proven by Volta, the applicability of machine learning on 3D visualization (ray tracing, specifically) turned the traditional tradeoffs of compute-versus-graphics upside down. No longer did features that didn’t enhance the conventional 3D graphics rasterization pipeline have to be considered a silicon tax to be eliminated for graphics-focused applications. That key premise set the stage for what a graphics-optimized Volta might look like … but while the premise held, the name did not. A graphics-optimized version did emerge, but it didn’t come bearing the Volta name.
Instead, Nvidia introduced Turing, a graphics-first GPU. Its first silicon incarnation, the mega-sized, flagship TU102 chip dedicated a significant amount of effort and transistor budget to advancing the stuff GPUs need to advance: 3D graphics performance for gaming and professional visualization based on essentially the same rasterization pipeline the industry has always relied on. Turing saw several significant enhancements to its fundamental 3D graphics programmable shader engine, the Streaming Multiprocessor (SM), especially in terms of chip registers and cache, and dialed up supporting infrastructure including external memory bandwidth. But all that represents expected steps along the tried-and-true GPU evolution path, taking on cost and complexity for features and performance the company is pretty damn sure ISVs and end users alike will value in the near term, if not immediately.
Nvidia leveraged in Turing much of what Volta brought, but without the assumed strip-down mandate for non-trivial AI acceleration features that past strategy might have suggested. With Turing, Nvidia architects not only didn’t strip out Tensor Cores, they improved on them, most notably increasing performance for lower precision 8-bit and 4-bit integer processing. Neither datatype is critical in graphics (not any longer, anyway), but can be used in place of 16-bit integer computation in AI inferencing. Adding lower precision support is likely inexpensive to add and in place of 16-bit execution, it would certainly improve inferencing performance and/or reduce power consumption.
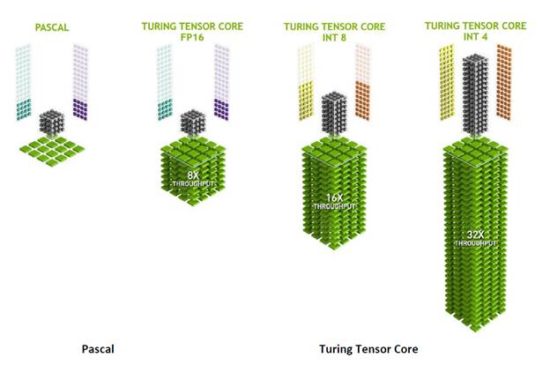
In addition to keeping in Volta’s Tensor Core, Nvidia took the further step of adding multiple (one per SM) instances of an entirely new core design: the RT Core. Short for ray tracing, the RT name signifies a very deliberate design addition, one intended to parlay Volta’s AI-spurred advancement for ray trace acceleration into realtime processing for more economical, graphics-focused GeForce and Quadro GPU products.
Specifically, the RT Core addresses a critical ray tracing computing task: determining whether a ray, shot from a viewport out into the scene actually intersects an object. Previously, this task had been executed by the GPU’s SMs, which proved to be cumbersome and inefficient. It is also one of those tasks that a traditional raster-based 3D shader wasn’t designed for, and therefore doesn’t do particularly well. With Turing, that job is now left to the RT Cores, freeing up the SMs to spend cycles on shader processing, which they’re more adept at executing.
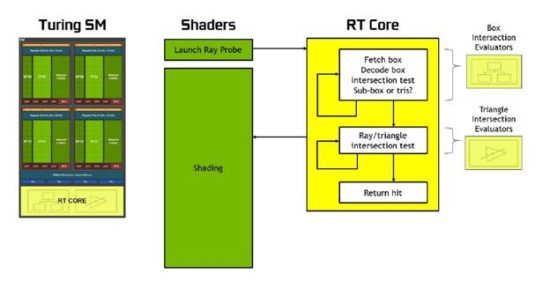
That goes for all Turings, not just the TU102
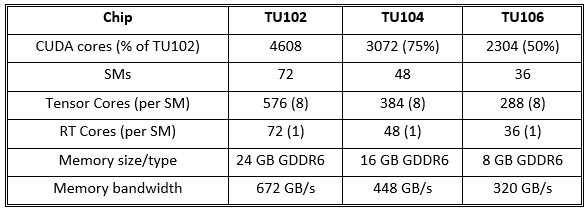
In addition to the TU102, Nvidia also previewed two smaller siblings to come, the TU104 and TU106 (very much tracking the progression of “graphics Pascals” GP102, GP104 and GP106) and in the process put to rest any notions that Nvidia might strip out Tensor Cores or RT Cores for the cost-reduced derivatives.
While the smaller TU104 (roughly 75% of a TU102) and the TU106 (around half) may drop a lower profile feature, both not only retain Tensor Cores and RT Cores, they retain the same ratio of CUDA cores to both Tensor Cores (8 per SM) and RT Cores (1 per SM). That is, as Nvidia pushes Turing down the price and product spectrum, it is not de-emphasizing either inferencing or ray tracing. No doubt, both represent capabilities Nvidia expects will best serve its long-term interests in serving markets new and old.
Nvidia NGX: Extracting more AI-acceleration of 3D visuals
No doubt enthused by the successful synergy of machine learning and graphics with ray trace processing, Nvidia researchers searched for other ways to extract more visual processing goodness out of Turing’s AI prowess. Extending on the DNNs employed in ray trace de-noising, Nvidia formalized NGX, an enhanced set of DNN-driven image-enhancement features. Nvidia does not see NGX today as a fixed set of features, but rather as an evolving and expanding toolbox of DNNs that can further harness machine learning for the benefit of Nvidia’s traditional visual markets. For Turing’s official launch, however, Nvidia is pitching four specific NGX features, exposed to applications in the NGX API.
- Deep Learning Super-sampling (DLSS), an accelerated version of super-sampling, which generally requires multiple passes through the 3D rasterization pipeline. Nvidia’s DLSS uses a DNN trained on high-quality images to analyze intermediate frames to come up with the best image.
- AI InPainting uses intelligence to enable content to be removed from images such as an errant telephone pole in a pristine scene of nature and filled with pixels similar to the surrounding scene to hide the removal. The technique is well known in imaging, but Nvidia’s AI speeds it up and makes the fill more convincing.
- AI Super Rez, similar to InPainting, Super Rez enables images to be scaled up or down without artifacts as the DNN can analyze the scene and fill in what isn’t there.
- AI Slow-Mo creates intermediate video frames utilizing a DNN to intelligently interpolate video frames to create intermediate frames that didn’t otherwise exist, fitting the both content and temporal behavior.

Datacenter benefits of Turing
I call Turing a graphics-first architecture, but graphics-first does not mean graphics-only. Rather, I’d argue Turing is better outfitted for datacenter applications than any previous GPU that could justifiably be called graphics-first. Current and emerging trends in data center applications using inferencing bode well for Turing’s successful adoption in servers. Nvidia obviously concurs (no doubt reflecting a deliberate pre-determined goal for the GPU), and has already announced one Tesla brand GPU built on Turing, the Tesla T4.
The reception for Turing in the datacenter should be a very welcoming one, given two key trends spurring adoption for server-side GPUs. First is the steadily growing and accepted use of GPUs to accelerate complex, floating-point intensive applications that lend themselves to highly parallel processing. Maximum throughput FP64 is critical for some of these applications, but not all, so Turing can certainly serve as a subset. Second is the more recent trend to employ servers as datacenter-resident hosts for remote graphics desktops, including both physically and virtually hosted desktops for gaming and professional usage. The growing appeal of datacenter-based graphical desktops is being fueled by computing challenges that have begun to overwhelm traditional client-heavy computing infrastructures suffering under the weight of exploding datasets and increasingly scattered workforces. And it’s worth noting that for hosting remote desktops, a graphics-first GPU design will be the more appealing than a compute-first one.
Nvidia’s tendency to think long-term has served it well in the past … and likely will again
For the first time since Fermi, Nvidia has built a graphics-first chip with costly features that don’t serve Nvidia’s traditional market focus, the 3D graphics rasterization pipeline. The key difference this time is that those features can make valuable contributions to improve visual performance and/or quality. And that means they’re not necessarily competing with more well-established “graphics features” for inclusion in Turing, at least not to the degree that features like fast-FP64 have.
Remember that despite both its early footholds and deep, successful penetrations in new computing spaces, Nvidia’s revenue, profitability and R&D budget depend largely on its GPUs’ ability to improve the experience of interactive 3D game play and professional visualization applications. And in the context of those applications today, the use of inferencing represents but an iceberg’s tip.
Realtime ray tracing among applications is promising but the market will need time to bootstrap; Turing-specific, developers today have zero demand in the installed base. Given that, Nvidia’s aggressive push with Turing, and its Tensor and RT cores, is not without short-term risk, despite the “unifying” combination of graphics, inferencing, and ray tracing.
In that context then, credit goes to Nvidia. Because as it’s demonstrated as often as any company I can think of, Nvidia is willing to take some short-term risk to aggressively pursue features and technology that have the potential to give the company a lead in an emerging space and further its long-term dominance. That’s what happened with CUDA and the compute-focused features in Fermi, eventually. Nvidia’s bet on GPU Compute opened up markets and opportunities precisely the way the company had hoped even if the transition wasn’t as smooth as the company might have wished.
As a unifying force, AI promises much longer legs than some previous, transient, shot-in-the-arm technology gimmicks or detours. The prospects and impact for AI on client-side, graphics-first, are both broad and deep, promising to penetrate virtually every segment of computing. The new paradigm Turing presents, pay off handsomely for Nvidia, establishing the company as a leader in technology that will become the new norm.