Well yes, of course they do but the company says they have Merlin on their side.

Recommendation systems can look at which items a person examines or buys, and then make a suggestion as to something similar they might like. For example, if someone ordered bread on-line, the system might suggest also getting some butter.
However, such systems can easily accumulate hordes of data in the process of profiling a customer or visitor.
With the rapid growth in scale of industry datasets, deep learning (DL) recommender models, which capitalize on very large amounts of training data, have started to gain advantages over traditional methods such as content-based, neighborhood, and latent factor methods.
DL recommender models are built upon existing techniques such as embeddings to handle categorical variables and factorization to model the interactions between variables. However, they also tap into the vast and rapidly growing literature on novel network architectures and optimization algorithms to build and train more expressive models.
The following diagram shows an example of end-to-end recommender system architecture.
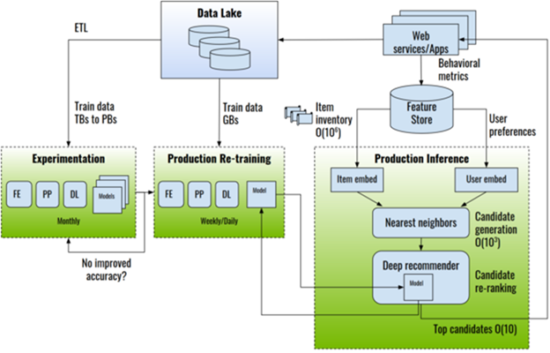
There are many challenges when training large-scale recommender systems:
- Huge datasets: Commercial recommender systems are often trained on large datasets, often terabytes or more. At this scale, data ETL and preprocessing steps often take much more time than training the DL model.
- Complex data preprocessing and feature engineering pipelines: Datasets need to be preprocessed and transformed into a suitable form to be used with DL models and frameworks. Meanwhile, feature engineering trials create numerous sets of new features from existing ones, which are then tested for effectiveness. In addition, data loading at train time can become the input bottleneck, leading to GPU underutilization.
- Extensive repeated experimentation: The whole data ETL, engineering, training, and evaluation process likely must be repeated many times on many model architectures, requiring significant computational resources and time. Yet after being deployed, recommender systems also require periodic retraining to account for new users, items and recent trends in order to maintain high accuracy over time.
- Huge embedding tables: Embedding is a universally employed technique nowadays to handle categorical variables, most notably user and item IDs. On large commercial platforms, the user and item base can easily reach an order of hundreds of millions if not billions, requiring a large amount of memory compared to other types of DL layers. At the same time, unlike other DL operations, embedding lookup is memory bandwidth-constrained. While the CPU generally offers a larger memory pool, it has much lower memory bandwidth compared to a GPU.
- Distributed training: While distributed training is continuously setting new records in training DL models in the vision and natural language domains, as reflected by the MLPerf benchmark, distributed training is a still relatively new territory for recommender systems, due to the unique combination of large data compared to other domains and large models. It requires both model parallelism and data parallelism, therefore it is hard to achieve high scale-out efficiency.
As a result, the combination of more sophisticated models and rapid data growth has raised the bar for computational resources required for training while also placing new burdens on production systems.
Here to save the day and meet the computational demands for large-scale DL recommender systems training and inference, Nvidia has introduced Merlin.
Merlin is an end-to-end recommender on a GPU framework for fast feature engineering and high training throughput. Merlin, says Nvidia, also offers fast experimentation and production retraining of DL recommender models, and low latency, high-throughput, production inference.
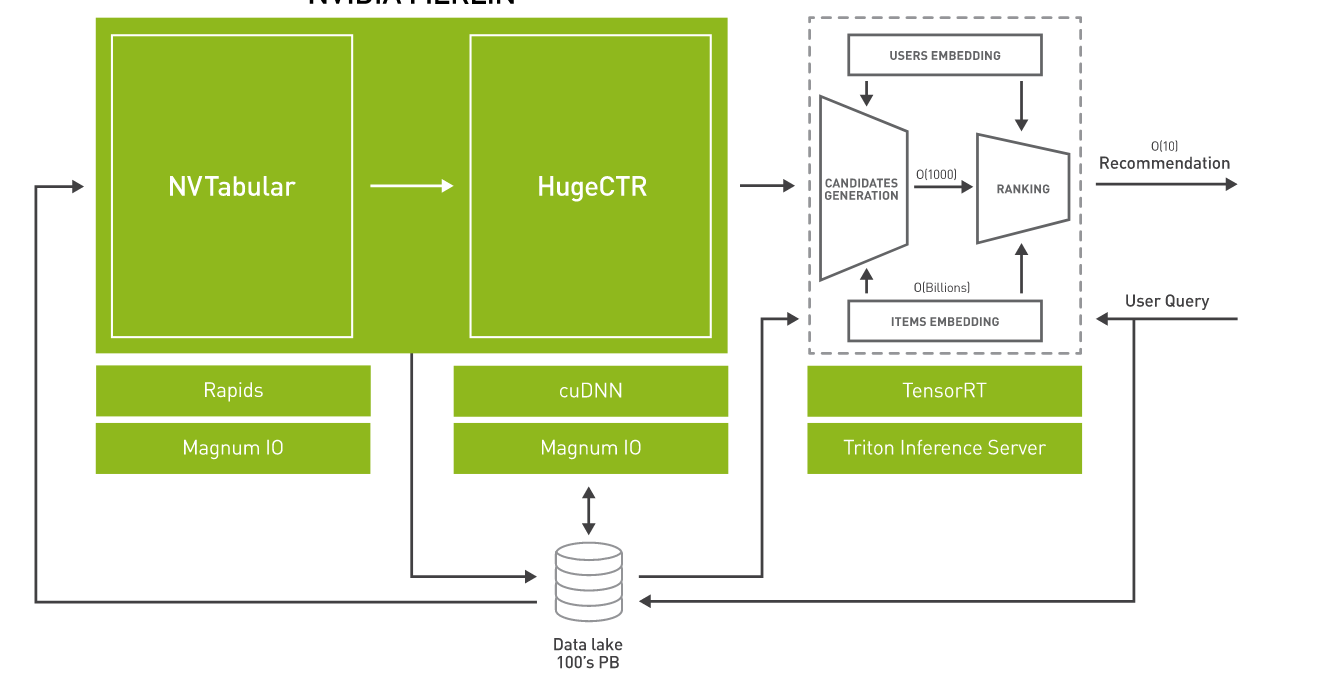
Merlin includes tools for building deep learning-based recommendation systems that provide better predictions than traditional methods and increase click-through rates. Each stage of the pipeline is optimized to support hundreds of terabytes of data, all accessible through easy-to-use APIs.
- Merlin ETL is a collection of tools for fast recommender system feature engineering and preprocessing on GPU.
- Merlin training is a collection of DL recommender system models and training tools.
- Merlin inference is Nvidia’s TensorRT and Triton Inference Server (formerly TensorRT Inference Server).
NVTabular is a feature engineering and preprocessing library, designed to quickly and easily manipulate terabyte-scale datasets.
What do we think?
The terminology of AI systems, in general, and recommendation systems, in particular, are arcane and mind boggling to the non-practitioner. Compounded by esoteric acronyms, it’s difficult to make sense out of what is being offered and its benefit.
But, one can model the problem in a thought experiment quite easily—e.g., the bread and butter example above. Think of all the times you’ve looked at something on the web out of curiosity and then how advertisements for that type of thing suddenly appear in every web search you look at thereafter. Or, if you’ve ever bought something on Amazon or from one of its competitors, how as you try to get to the check out page you are offered suggestions, discount coupons, and quantity discounts. That’s all done by inference systems in the cloud that are training in realtime on the data you provide in searching or buying. It’s lighting fast, remarkably focused, and, as Huang says, will make users feel as if they have theirs on private and customized web.
The downside is it corrals you and stamps you with a profile that might even distract you away from alternative solutions. The even more sinister aspect is biasing toward brands, which is a current acquisition being leveled at Amazon by the US government.
But how is that any different than car or clothing salesman offering you accessories and trying to “sell you up,” top more expensive items? It’s not, and it’s the name of the game in sales to maximize the sales event. New customers are very expensive to get, and when you get one, or even a prospect you want to make the most of the salesperson’s time, or in this case, the AI’s time.
And, more times than not, you will be delighted with what is being offered to you. Many times, it’s things you didn’t know about. Overall, we see this as a good thing, and not a threat.