Alex Herrera takes stock of AMD’s latest hardware introductions and notes the company has an edge on Intel and a serious play against Nvidia in the data center.
If Las Vegas placed odds on what news AMD would break in San Francisco at its Next Horizon, the heavy favorites would have been clear: the official announcements of both Zen 2 processor technology and the first 7-nm device based on Zen 2, an abundantly-core’d Epyc CPU for server and workstation applications. Both have been on corporate roadmaps and both chatter and reason would indicate the time for both had come. And if there was any doubt remaining, Intel eliminated it a mere two days before the convening of Next Horizons. Clearly looking to steal some limelight from its upstart rival, Intel fired a pre-emptive strike on AMD’s next-generation datacenter plans—just prior to AMD’s summit—by announcing its own “Cascade Lake” Xeon Scalable series offering a big jump to 48 cores per chip.
So both industry prognosticators and the rival alike had it right. Zen 2 and Rome headlined AMD’s event. Arriving in 2019 under the Epyc brand and “Rome” platform (as well as presumably desktop), the Zen 2 generation processor is AMD’s vehicle for pioneering the much-anticipated transition to TSMC’s 7-nm FinFET process node. But Rome didn’t represent the only silicon AMD wanted to show off, as it introduced two new datacenter-focused GPUs from the other half of its business: the 7-nm-enabled Radeon Instinct MI60 and MI50.
7 nm the linchpin for AMD’s 2019 plans
It’s no secret that 7-nm silicon is the the common thread and linchpin to AMD’s 2019 product plans. For once, AMD can claim a legitimate edge over chief CPU rival Intel in CMOS process technology. Now, bear in mind that it’s not fair to simply compare the digit in front of the “nm” suffix to judge superiority, particularly as the industry pushes up against the physical barriers constraining Moore’s Law (at least as it relates to CMOS technology). But given Intel’s well-documented struggles bringing volume 10 nm on line, AMD’s decision to hook its wagon to TSMC’s process train has proven a wise one. With TSMC’s 7 nm apparently yielding well, both AMD’s CPUs and GPUs the beneficiaries of AMD’s choice.

The first architectural details of Zen 2
Top on the list of 7-nm beneficiaries is AMD’s Zen processor. AMD claims it’s been able to leverage 7 nm to deliver 2× the density in second generation Zen 2 processors. Accordingly, compared to Zen, Zen 2 can deliver up to 2× the throughput (at max power, presumably), around 0.5× power (at same performance) and/or around 1.25× performance (at the same power). Zen 2 microarchitecture enhancements most notably include the following:
- Improved instruction throughput
Core counts continue to climb, and AMD is happy to use them as a primary performance metric for comparison, but the truth is both AMD and Intel need to continually dial superscalar knobs to increase single-thread performance. Toward that end, AMD went for improved branch prediction and pre-fetching, supported by a larger op cache in Zen 2.
- Floating point throughput up 2 × 2 = 4×
With Zen 2, AMD doubled the floating-point datapath width to 256. Doubling the width in combination with doubling the overall density enabled AMD to deliver up to a 4× increase in FP throughput. Supporting the increased compute throughput, designers doubled load-store bandwidth and dialed up dispatch/retire bandwidth to minimize the chances the higher throughput ALUs would be starved of data.
- Security improvement
With Zen 2, AMD got the chance to harden software patches mitigating the notorious and well-documented pre-fetch based bugs like Sceptre.
2nd generation Infinity Fabric with heterogenous process chip(let)s
In conjunction with the introduction of the Zen 2 generation architecture and platforms, AMD announced the second generation of its Infinity Fabric. Beyond serving as a link between multiple CPUs and between multiple GPUs in a system, Infinity Fabric is the primary tool the company employs to build its high-core-count CPUs, like Threadripper and Epyc. The company combines multiple chiplets in a single package using Infinity Fabric.
2019’s Rome Epyc processors
Previewed at AMD’s Next Horizons event in November 2018, Rome Epyc is expected to ship in 2019 (we’d have to imagine first half). Delivering up to 64 second-generation Zen 2 cores per socket, 2019’s Rome Epyc platform consists of 8 × 8 core Zen 2 chips connect in-package via Infinity Fabric 2, complemented with 14-nm I/O. Why not 7-nm analog and I/O as well? Two reasons: first, 14 nm delivers the performance and capability necessary, and shrinking to 7 nm is significantly harder for analog than digital. Call that a bonus of AMD’s multi-chiplet approach to building high-core-count Zen processors: support for heterogeneous silicon processes.
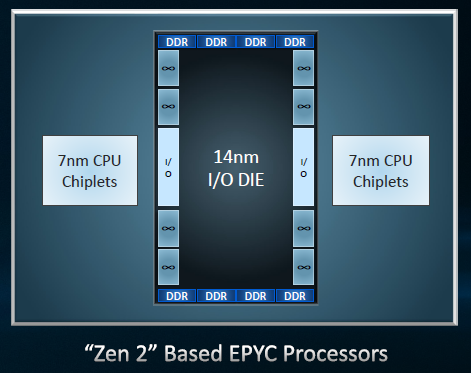
With double the core count as Naples Epyc, Rome can deliver up to 2× throughput per socket. And given Zen 2’s improved floating-point performance, the gain climbs to 4× in floating point throughput.
Socket compatibility across three Epyc generations
Compatibility with existing motherboards and systems is not always possible moving generation to generation, but it’s a highly desirable goal, especially if you’re looking to leverage every possible drop of momentum created by first generation Epyc. Accordingly, AMD chose to maintain compatibility not only with previous generation Naples, but also announced that sockets wouldn’t be changed for next generation either, promising system builders an easy upgrade path to the upcoming Zen 3 based Milan. The compromise is that I/O lanes and memory interface widths are fixed for three generations, the latter fixed to the original Epyc’s eight memory channels (for Rome, that’s one per 8-core chiplet). That’s a minor tradeoff, given both the strong business motivation in play and that Epyc has been well spec’d in those areas from the beginning.

Zen 3 for 2020
In conjunction with the Zen 2 and Rome unveilings, AMD announced Zen 3 was “on track” for 2020 and Zen 4 coming is heavy in the design phase.
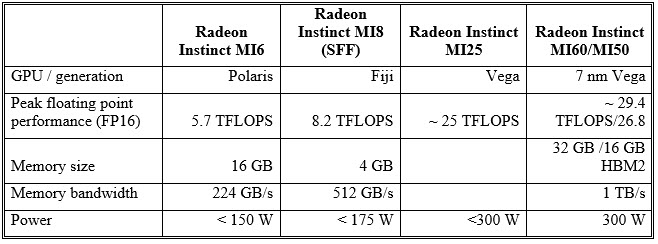
AMD’s Radeon Instinct MI60/MI50 GPUs: Vega comes to the datacenter
Zen 2 and Rome shared top billing, but given the timing and datacenter focus for AMD’s event, the GPU side of the company’s business got in on the Next Horizon’s action. Leveraging a Vega shrink to 7 nm, AMD added two new Radeon Instinct datacenter GPU products, the MI60 and MI50, both leapfrogging the previous 14-nm Vega Radeon Instinct MI25. The MI60 is the flagship, with the MI50 modestly cost/performance reduced, with clocks dialed back and memory footprint cut in half (from 32 GB to 16 GB).

AMD claims the MI60 can deliver 1.24× higher performance (at the same performance) or 50% lower power consumption (at the same frequency) of the previous top-end Radeon Instinct MI25 (the first Vega-based SKU in the line). The MI60 supports both end-to-end ECC (register and memory datapaths) and fast FP64 processing (1/2 speed of FP32), resulting in what AMD has claimed as the “world’s fastest FP64 and FP32 (PCIe capable) GPU”. Architects also leveraged HBM 2 memory to deliver 1 TB/s of peak memory bandwidth.
The MI60 is PCIe 4.0 compliant for 64 GB/s CPU-to-GPU bandwidth, complementing the 100 GB/s per link Infinity Fabric support (in ring topology) to create multi-GPU clusters for HPC/supercomputing applications. In terms of performance metrics, AMD says that the MI60 can deliver 6.717 DGEMM TFLOPs versus the MI25, or roughly an 8.8× speed-up. For machine learning, AMD claims the MI60 can run RESNET-50 2.8× faster. Furthermore, AMD says it’s seeing near-linear scaling of RESNET-50 performance up to 8 GPUs, thanks to Infinity Fabric interconnect.
The growing value proposition for datacenter GPUs: not just one but three compelling applications
The value proposition datacenter-focused GPUs like Radeon Instinct are setting forth is continuing to gain appeal, given two key trends spurring adoption. First is the steadily growing and accepted use of GPUs to accelerate complex, floating-point intensive applications that lend themselves to highly parallel processing. Second is the cloud’s focus on machine learning, and GPUs are currently positioned as the AI-acceleration leader, particularly where flexibility is concerned. And third is the more recent trend to employ servers as datacenter-resident hosts for remote graphics desktops, including both physically and virtually hosted desktops for gaming and professional usage. The growing appeal of datacenter-based graphical desktops is being fueled by computing challenges that have begun to overwhelm traditional client-heavy computing infrastructures suffering (particularly) under the weight of exploding datasets and increasingly scattered workforces. Radeon Instinct can handle a range of workloads, AMD first and foremost highlighting four: cloud gaming, HPC, AI, and graphics desktop hosting. (While separate markets, we’d be tempted to merge cloud gaming and graphics desktop hosting as a common use case, for the aforementioned total of three.)

Now consider the procurement and investment decisions facing both third party and enterprise datacenter providers. One of those decisions is to decide to what extent to populate GPU hardware among a sea of servers. Should GPUs be deployed broadly, with a wide range of product performance and capability points, or should they be selected for sparing deployment, justified by specific demand and use cases? With GPUs from both AMD and Nvidia showing an increasing proclivity for machine learning, compute (at least a subset) and hosting remote graphical desktops, those outfitting datacenters can more easily justify the decision to go forward with more GPUs rather than fewer.
That flexibility not only applies for one GPU to one application but in the case of all three spaces, the ability to combine or share GPUs across multiple applications is of significant value. Radeon Instinct supports aggregating multiple GPUs to serve one client (especially HPC and AI) or sharing one virtualizable GPU among multiple clients for graphics desktop hosting. Radeon Instinct employs the same Infinity Fabric as Zen CPUs to enable high-speed bandwidth between GPUs in multi-GPU configurations.

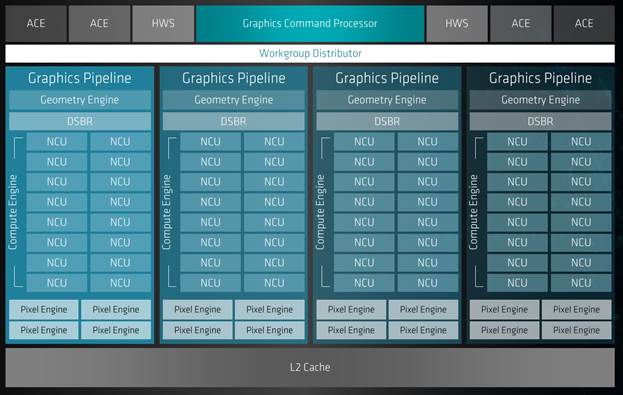
The 7-nm Vega microarchitecture
The bulk of the 7-nm Vega’s goodness comes courtesy of the shrink, allowing more Next-Gen Compute Units (NCUs, the atomic computing element of the architecture) to be populated, thereby driving up throughput. But AMD did make significant architectural changes to the NCU as well. Most notable for the data center: ECC (Error Correction Code) support across all register and memory storage, new instructions, and improving multi-precision throughput.
Though certainly nice to have, ECC has never been a critical feature for a GPU performing 3D graphics tasks. Neither has fast 64-bit floating point performance (FP64), precision overkill for 3D graphics. Similarly, optimized performance across a range of sub-32-bit integer and floating point formats aren’t in particular demand among traditional visualization markets, as FP32 (single precision, 32-bit floating point) has long been the workhorse for the 3D graphics pipeline.
But remember, GPUs aren’t just for 3D graphics anymore, especially when those GPUs are targeting the datacenter. ECC and fast FP64, for example, are must-haves in certain corners of the HPC markets that Radeon Instinct GPUs serve. And lower precision formats are now of interest, as bit-depths down to four can suffice for machine learning applications, particularly inference, and a sensibly designed 32-bit datapath, for example, ought to crank through a lot more 4-bit operations (8×, ideally) than 32-bit math. Similarly, the new instructions added to NCU support weren’t justified by demand for graphics but rather specifically geared to multi-precision, neural network processing.

Thanks to the 7-nm process’ superior density, AMD was able to populate 64 NCUs (for the MI60, 60 in the MI50) and still keep die size reasonable at 331 mm2 (3.2 billion transistors total).
With more NCUs, now enhanced for superior multi-precision throughput, AMD can claim some dramatic speed-up figures for the MI60 relative to its predecessor at the top of the Radeon Instinct line, the MI25. For FP16, the company claims around 20% faster execution, but the big gains are in 8-bit and 4-bit integer math, where the MI60 runs 140% and 380% faster according to AMD. Given the aptitude of both the MI50 and MI60 for high-performance multi-precision workloads AMD is positioning the two new cards across the application/precision spectrum. They run faster at low bit depth but can still manage high performance for FP64, with only a 50% performance penalty relative to FP32 (often, it can be far slower).

ROCm 2.0 released supporting HPC, AI, and virtual graphics desktops
The merits of any hardware are moot if developers can’t program it efficiently. And that goes double for emerging computing applications like machine learning, where there isn’t one API or environment that covers virtually all your bases. Toward that end AMD is building Radeon Instinct GPU support around MIOpen, a free, open-source library for GPU accelerators to enable machine intelligence applications, supporting standard routines including convolution, pooling, activation functions, normalization and tensor format. Introduced in conjunction with 7-nm Radeon Instinct MI160/MI50 was version 2.0 of ROCm, adding additional support (in particular) for machine learning frameworks and middleware.

2019 looking rosy, especially in CPUs
Thanks both to its own engineering execution in design, as well as TSMC’s in 7-nm manufacturing, AMD’s ducks are lining up nicely for a bullish 2019. In the case of Epyc: AMD appears poised to take significant CPU share in the datacenter, thanks to its successes dovetailing with Intel’s process struggles. 7 nm will boost AMD’s competitiveness in GPUs as well, but particularly in the datacenter. However, it’s facing a much better positioned rival in Nvidia. We expect to see Epyc and subsequent 7-nm Ryzens and Threadrippers build off their existing footholds in CPUs, while in GPUs, AMD’s advancements should at least help maintain a healthy competitive posture.