AudioCraft is an AI tool developed by Meta that allows users to generate high-quality and realistic audio and music from text prompts. It consists of three models: MusicGen, AudioGen, and EnCodec.
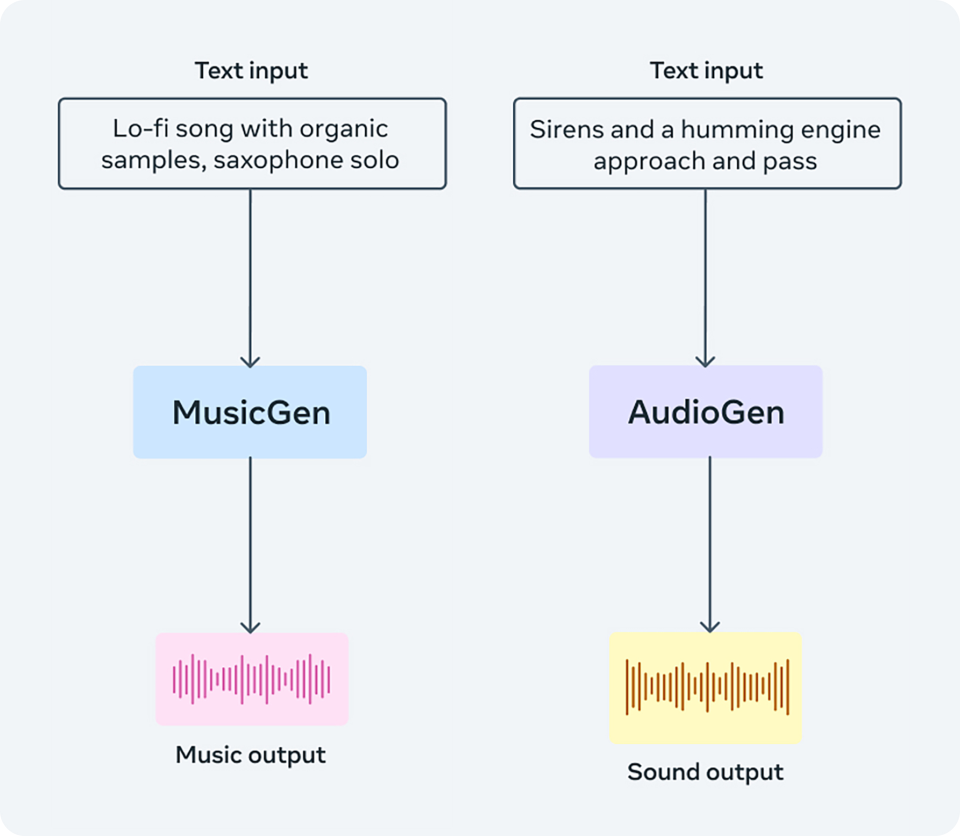
- MusicGen: This model generates music from text prompts. It has been trained using Meta-owned and specifically licensed music, allowing it to create musical compositions based on the given textual input. MusicGen was trained on roughly 400,000 recordings along with text description and metadata, amounting to 20,000 hours of music owned by Meta or licensed specifically for this purpose.
- AudioGen: This model generates audio, particularly sound effects and environmental sounds, from text prompts. It has been trained on public sound effects, enabling it to produce realistic audio representations based on the provided text.
- EnCodec: This is the decoder component of the system. It has been improved to enhance the quality of music generation and reduce any unwanted artifacts that may have been present in previous versions.
The exciting part is that Meta is open-sourcing these models, making them accessible to researchers and practitioners.
The development of generative AI has been more focused on images, videos, and text in recent years. Still, AudioCraft aims to bridge that gap and make generative audio more accessible and straightforward for people to use and experiment with. Creating high-fidelity audio, especially music, is a complex task, as it involves modeling intricate patterns and structures at different scales.
The AudioCraft models have been designed to produce high-quality audio with consistency over long periods, and they are user-friendly. They simplify the process of building generative audio models compared to previous work in the field. With access to the code and models, users can build upon existing work, develop new sound generators, compression algorithms, and music generators with ease.
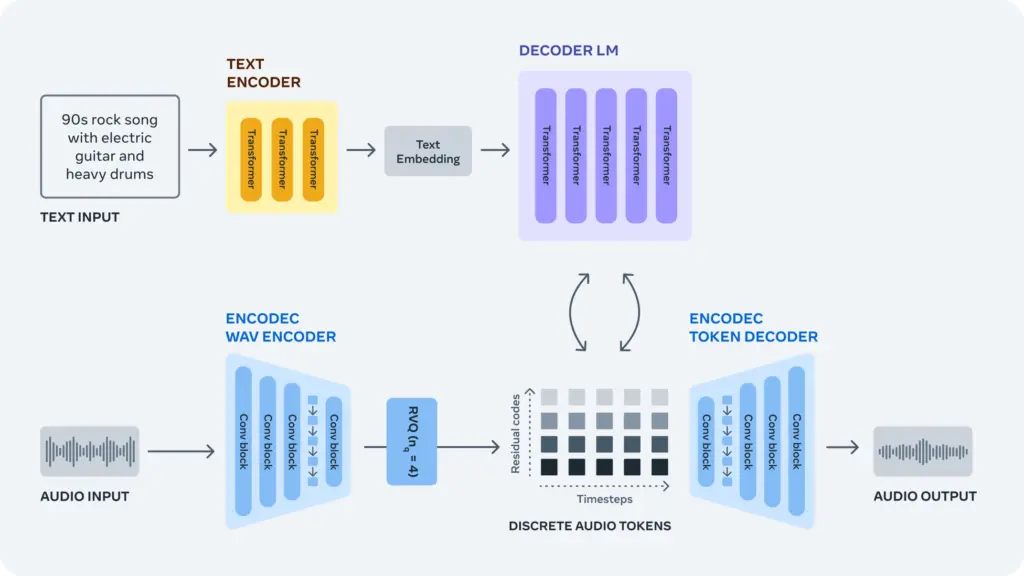
Google has its own AI music model, too. MusicLM is capable of generating high-fidelity music from text descriptions. Using hierarchical sequence-to-sequence modeling, it produces music at a sample rate of 24 kHz, ensuring audio quality and consistency over several minutes. Google claims that MusicLM adheres better to given text prompts that previous systems, and it can also be conditioned on existing melodies, transforming them according to the described style. To support further research, Google has released the MusicCaps dataset, containing 5.5k music-text pairs with detailed descriptions provided by human experts.