By Bob Cramblitt
There’s a statement popularized by Mark Twain that describes the often-deceptive power of numbers: “There are three types of lies: lies, damned lies, and statistics.”
Among people concerned with computer performance, the saying rears its head in a slightly altered form: “There are lies, damned lies, and benchmarks.” Like most wide-sweeping statements, this one contains a kernel of truth. The mistake is when it is applied in broad brush strokes to describe all benchmarks.
Simply put, no two benchmarks are the same. The differences evidence themselves in myriad ways: what the benchmark measures, how it measures, what models and operations are used to measure, who is behind the benchmark and what they have to gain, and most visibly, what metrics are used to characterize the performance.
Getting close to the application
Alex Shows, chair of the SPEC Workstation Performance Characterization (SPECwpc) subcommittee, is passionate about the subject of metrics and what they should mean.
“In an ideal world, benchmark metrics should represent the operations, data, and conditions that one would encounter as part of some task that produces useful work. The exactness of that match is the crux of the challenge of creating better benchmarks: making difficult decisions about what is most representative and therefore relevant to users.
“Unfortunately the benchmarking world is plagued with illegitimate measures of performance; metrics derived from novelty bits of code that bear little or no resemblance to anything actually used in the real world.”
“Real benchmarks measure performance using instructions and data sets that closely resemble those of real applications. SPECworkstation 3’s lavamd workload, for example, runs a molecular dynamics simulation just like software used today in the medical field.”
Getting to the core of what an application does, how it does, and which operations are most important to users’ day-to-day work is the crux of the challenge for benchmark organizations such as SPEC. It requires close coordination between independent software vendors (ISVs) who develop the applications and the organizations creating tests that accurately characterize the performance.
Among the issues to be considered include:
- Accurately tracing or recreating the unique processing paths that applications take for critical operations.
- Providing models that are representative of those used in the real world.
- Applying weighting for different tests based on their importance within users’ typical workflows.
- Incorporating new application features into updated versions of benchmarks.
- Ensuring that scoring is consistent and repeatable.
Beyond speed
Benchmarking isn’t meant to be a speed race, but a technique to help improve user experience, according to Ross Cunniff, chair of the SPEC Graphics Performance Characterization (SPECgpc) subcommittee.
“People often mistake units—MFLOPS, FLOPS, FPS, LPM, etc.—for benchmark metrics. Just because you can run a test and generate these types of units doesn’t make your test a benchmark with meaningful metrics.”
Metrics for a legitimate benchmark, according to Cunniff, meet three key criteria:
- Repeatability: Ensuring that the same operations are benchmarked on all configurations and that metrics are repeatable over many test runs. Rule of thumb is a variation of up to 5% is generally acceptable.
- Accuracy: Do the metrics reflect reality? A good metric measures work that is actually being done as the user would typically do it. There also should be a means to verify that testing was done properly to arrive at that metric.
- Reportability: Metrics should be defined and reported in ways that help users track performance over multiple builds and changing variables such as OS, CPU, GPU driver, and memory size.
The importance of granularity
One number that purports to sum up everything about performance is as tempting as a five-star rating system for movies or products, but it is a very limited metric, according to Shows.
“One number can be useful to see a high-level summary of the data when making broad comparisons across very different workstations, but as those differences become more difficult to distinguish, more granular levels of scoring are needed.”
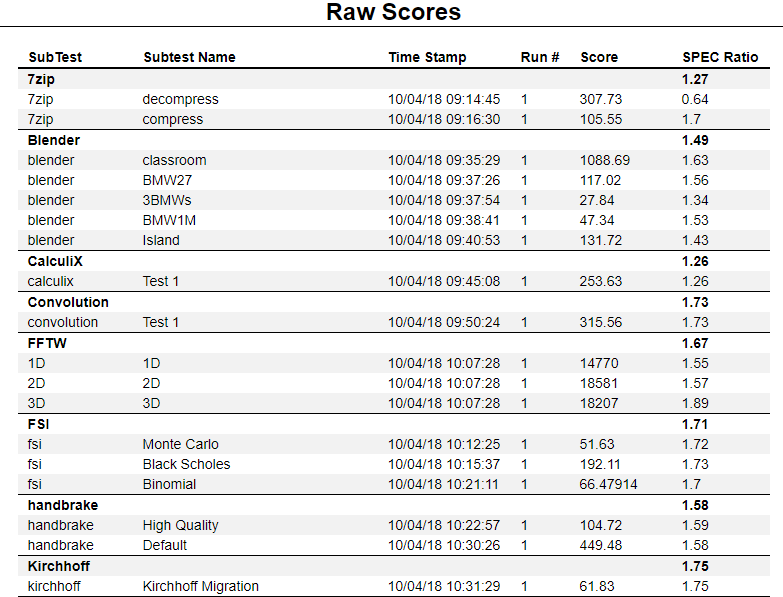
Granularity is evident in the SPECviewperf 13 graphics performance benchmark, which includes nine distinctive workloads, called viewsets, representing professional CAD, media and entertainment, energy (oil and gas), and medical applications. There are 90 tests within the suite that record performance for wireframe, shaded, shaded with edges, shadows, and other graphics modes. Metrics are computed as average frames per second (FPS), which is the total number of frames rendered divided by the time it takes in seconds to render those frames. FPS values are then compiled to compute the composite score using weights for each test based on user experience.
Similarly, the SPECworkstation 3 benchmark generates metrics for more than 30 workloads containing nearly 140 tests exercising CPU, graphics, I/O, and memory bandwidth. The workloads are divided by application categories that include media and entertainment (3D animation, rendering), product development (CAD/CAM/CAE), life sciences (medical, molecular), financial services, energy (oil and gas), general operations, and GPU compute.
Individual scores are generated for each test and a composite score for each category is calculated based on a reference machine, yielding a “bigger is better” result.
“Benchmarks like SPECviewperf and SPECworkstation maximize variation in those areas that have the most impact on performance,” says Shows. “It’s important to capture several levels of geometric and shader complexity to best represent the wide gamut of possible scenarios a user might create and interact with when using a particular application.”
Benchmarks such as SPECapc that run on top of an application contain metrics to measure the performance of major features users rely on in their day-to-day work.
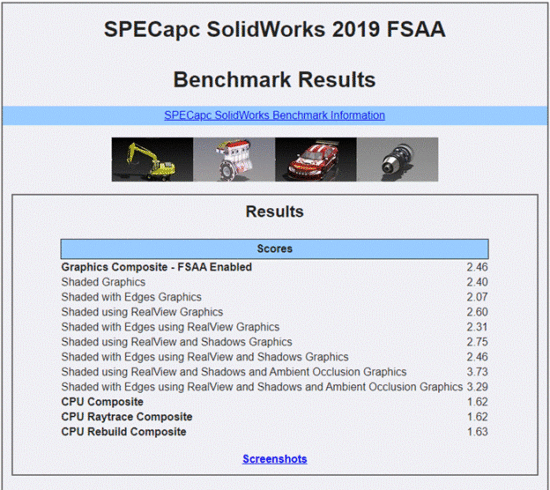
A Solidworks benchmark, for example, should measure features such as order-independent transparency (OIT), full-scene anti-aliasing (FSAA), standard and enhanced graphics modes, and CPU ray tracing for models ranging in size and complexity.
A Maya benchmark should measure features such as CPU, GPU interactive, GPU animation, and GPGPU performance for models that are characteristic of those found in special effects, gaming, 3D animation, and architectural visualization applications.
In benchmarking, more is good
Beyond measuring the panoply of operations within an application, there is also value in using benchmarks to test discrete functionality, according to Chris Angelini, president of Texpert Consulting Inc., a company that tests hardware for top manufacturers before products reach the retail market.
“An ideal performance metric is both accurate and precise,” says Angelini. “It can sometimes be difficult to achieve precision with benchmarks based on real-world workloads, particularly if a trace doesn’t put sufficient load on the subsystem you’re trying to isolate. Metrics from synthetic benchmarks are useful for things like measuring the impact of a new feature, comparing cache structures, and measuring the overhead of an API.”
Good benchmark metrics should be able to go from shallow to deep. Composite numbers can be used to summarize performance for CPU, GPU or storage, for example, but there also must be the ability to dive into the lower depths of individual tests to discover those places where bottlenecks reside.
Whether it is a benchmark that runs on top of an application, a synthetic one that recreates an application’s typical workloads and operations, or a benchmark that measures a specific area of functionality, the more you can measure and quantify through metrics, the better.
“Lord Kelvin, known for the international system of absolute temperature, might have said it best,” says Cunniff. “‘When you can’t measure it, your knowledge is of a meager and unsatisfactory kind.’”
Bob Cramblitt is communications director for SPEC. He writes frequently about performance issues and digital design, engineering and manufacturing technologies.