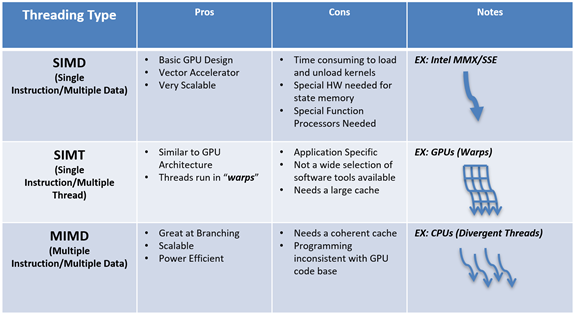
If SIMD is good, MIMD will be great.

The traditional 3D graphics pipeline is now 60 years old—is it time to reimagine how 3D graphics should be processed and displayed? In pursuit of greater display acuity, pixel densities are increasing in spatial resolution and color depth. In pursuit of greater realism, triangles, the basis for 3D models, are increasing in density and shrinking in size such that there can be several within one pixel. The combination of these two factors is increasing the processing load exponentially while at the same time there is a drive for much higher refresh rate, as much as four times greater. And it’s not just PCs and TVs, mobile devices are keeping pace with higher resolution displays and the constantly rising pixels/inch ratio. The industry has been asking for decades, when will we have photographic quality images on a digital display? And what technology will enable that?
Added to the increasing demands for display quality and speed, GPUs are being used for AI training and computational acceleration, imaging and photogrammetry, vision systems and point-cloud translations, and simulations of almost everything imaginable from molecules to fighter aircraft to nuclear energy.
On the software side, the GPU has to be compatible with a myriad of APIs for various industries and applications as well as platforms from smartphones to game consoles, robotics, to aircraft cockpits, television, and massive display walls.
Dealing with all these demands are today’s GPUs—single instruction, multiple data, multiple thread—SMID/T machines—vector processors. By putting thousands of the SMID/T cores together with a common dispatch system, extremely fast and powerful parallel processors are built. Designed originally to deal with the parallel display operations needed for graphics, they have been adapted to computational and other applications with parallel threaded data structures.
Designed originally for graphics, and based on graphics APIs, today’s SIMD/T GPUs replaced fixed-function hardware engines used to rasterize points, lines, and triangles and allowed for rasterization and graphics primitives to be generated with compute shaders. They work and work exceptionally well but are based on a linear pipeline with frequent (and often redundant) memory transfers. It’s not uncommon for today’s GPUs shaders to require branching callbacks that stall or delay the pipelining operations. For example, game engines go through multiple compute layers to realize the final color of a pixel. Some of these processes include physical simulations, AI calculations, multiplayer state-space considerations, and audio computations, all of which may be performed on the GPU. So the linear pipeline may be inefficient to accommodate all of these computational requirements and a more acyclic graph may be a better option. And graphics is no longer just about converting a 3D model into a 2D image but also involves the acquisition of a 3D model from a 2D image!
GPUs have been augmented with additional functions such as data CODECs, AI Tensor cores, ray tracing cores, audio processors, and communication ports. The GPU has become an SoC with its own programming languages, APIs, compilers, and in some cases its own sub-OS.
And, GPUs still need to communicate with a host CPU and set up data structures in GPU memory. That is necessary in order to initiate the GPU rendering/compute process. In addition, there is the need to link to peripherals, I/O, and file systems.
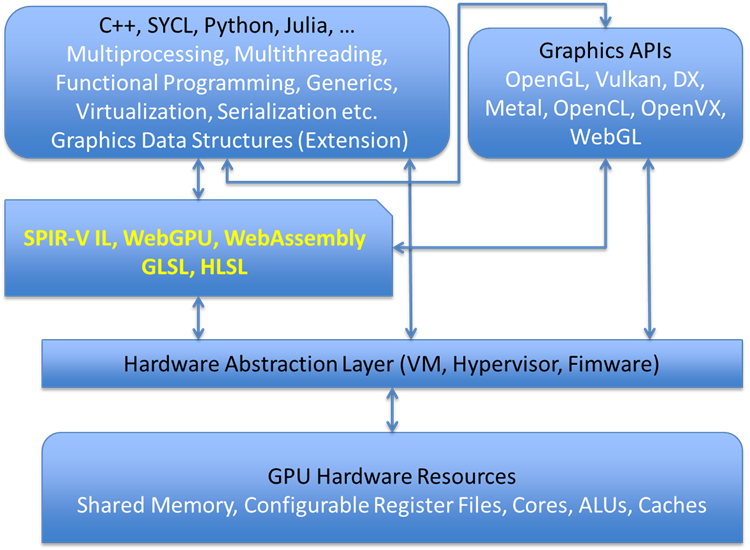
Today’s GPUs also have a complex software structure that can involve multiple compilers, libraries, and programming languages. Higher level abstract programming languages often burden the system and add latency.
In preparation for a new structure, other ideas for content development such as realtime photogrammetry and new ways to compress and store that content must be considered. These new structures will also need to address the usability of such content, such as embedded semantic tags that tell us what this content is and how to use it.
How can we render such content? Ray tracing? What about image-based rendering (IBR)? If the geometry resolution on a display is equal to or smaller than the pixel resolution, it makes no sense to spend gigaflops figuring out the color of a single pixel. In this regard, IBR may be the ideal solution, at least in the mobile space if it can do IBR very fast.
Smart-memory technology should be considered where the capture end of the pipeline (i.e., CCD device) is tightly coupled to the processor in a 3D stacked die ASIC with through-silicon via (TSVs) to connect the various layers including a memory layer.
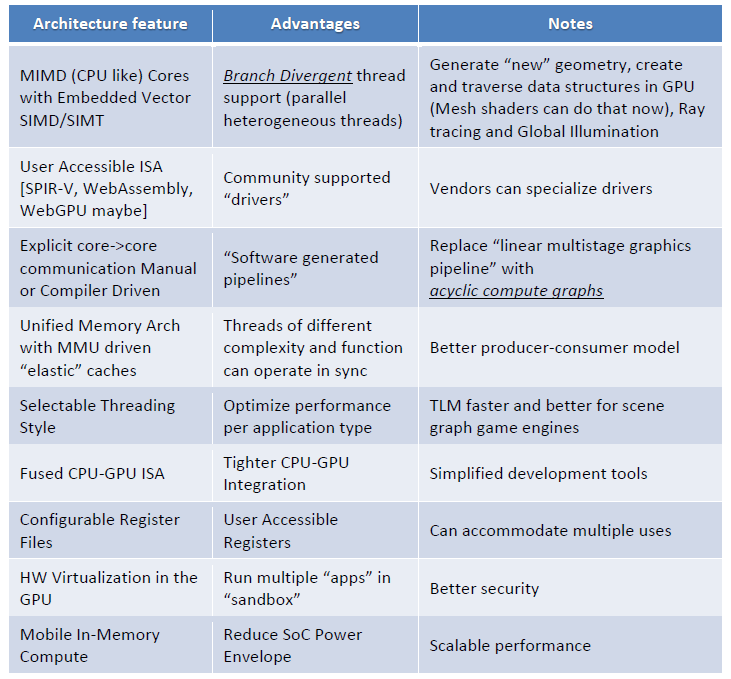
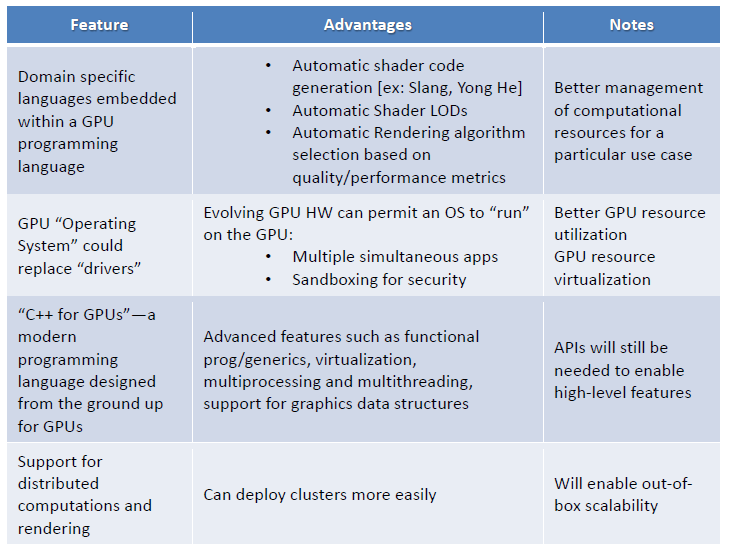
In addition to added and different hardware features, a new GPU construct would also be expected to take on new divergent workloads as listed in the following table.
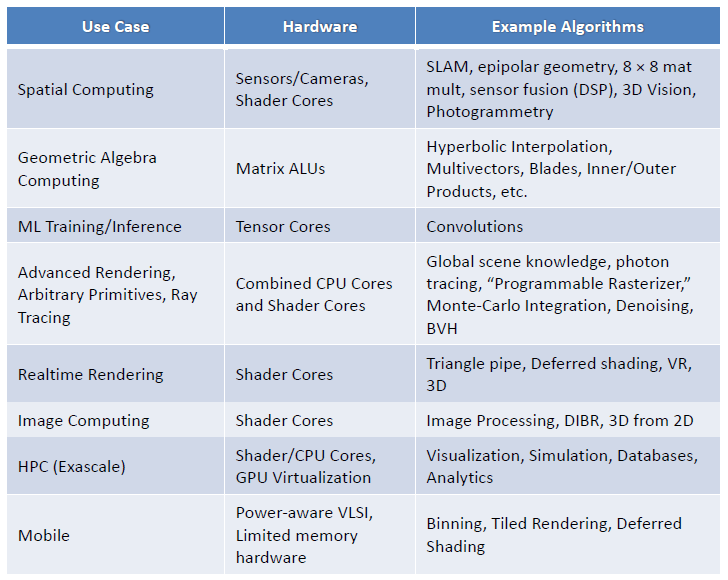
The installed base of systems and software (from OS to API and apps) need to be respected and taken into consideration. It would be foolhardy to propose a new GPU structure that would attempt to obsolete the existing processors and software.
One can consider the GPU as an SoC that combines CPU, SIMD and LUTs, AI, Codec, audio, communications, and RPU [Ray Processing Unit] as multiple and important compute structures that can independently generate and modify pixels
The next-gen graphics SOC will include CPU, GPU AI, RPU, and other cores all in one device. It will have access to unified global smart memory along with managed coherent caches to allow a seamless blend of pixels from multiple core types.
One candidate for the construct is SPIR-V as a unifying intermediate language to add new features. On top of it will be built new driver sets to support new use cases. One possible model is MIMD on SIMD Hardware (Henry Gordon Deitz, http://aggregate.org/MOG/).
The MIMD (Multiple Instruction, Multiple Data) execution model is more flexible than SIMD (Single Instruction, Multiple Data), but SIMD hardware is more scalable. GPU (Graphics Processing Unit) hardware uses a SIMD model with various additional constraints that make it even cheaper and more efficient, but harder to program. Is there a way to get the power and ease of use of MIMD programming models while targeting GPU hardware?
Interestingly enough, the mobile SoC is already there. A device such as the Qualcomm Snapdragon already integrates all of these cores into a cohesive whole. But the software stack is not yet smart enough to recognize the cores as a unified compute framework and different SDKs (software development kits) are required to program each core. If that barrier could be overcome, we could have a formidable smart processing engine that can be deployed in a variety of next-gen application scenarios. Intel is already at the forefront with the OneAPI model. Soon others in the industry will undoubtedly follow and we can truly begin to explore and understand what heterogeneous computing has to offer.
In essence, this really is existing technology combined in a new way using a unified memory architecture. It’s really a family member but a unique species.
Epilog
In 2018, Atif Zafar concluded that a more robust GPU architecture was needed to deal with the increasing density of displays, the horde of data being generated that needed to be displayed, and the drive to move to image-based rendering. What started as a thought experiment gained traction as the obstacles they listed slowly fell aside. By 2019, he had enough good ideas to formulate a proposal to the industry at large and a proposal for a new GPU integrated into RISC-V cores was presented at Siggraph 2019. In 2020, Zafar submitted a proposal to Siggraph to conduct a Birds of a Feather (BOF) panel and in August 2020 the panel was held virtually.
You can follow the commentary on Atif’s Blog and signup for the Slack NextGenGPU channel (linked on the blog) if you’d like to contribute to the conversation.




