A technical paper submitted at Siggraph 2020 offers promising results.
Researchers from the Chinese Academy of Sciences and the City University of Hong Kong have developed a deep learning-based solution for sketch-to-image translation. The team presented their technical paper (requires login) at Siggraph 2020 that concluded recently. They demonstrated a system that uses rough or incomplete freehand sketches and produces high-quality realistic face images (resolution: 512 × 512), which faithfully respect the input sketches. Here faithfulness means the degree of fitness to input sketches.
Other researchers have also tried to generate images from incomplete sketches. But their methods have required relatively accurate inputs, which is difficult without professional-level drawing skills.
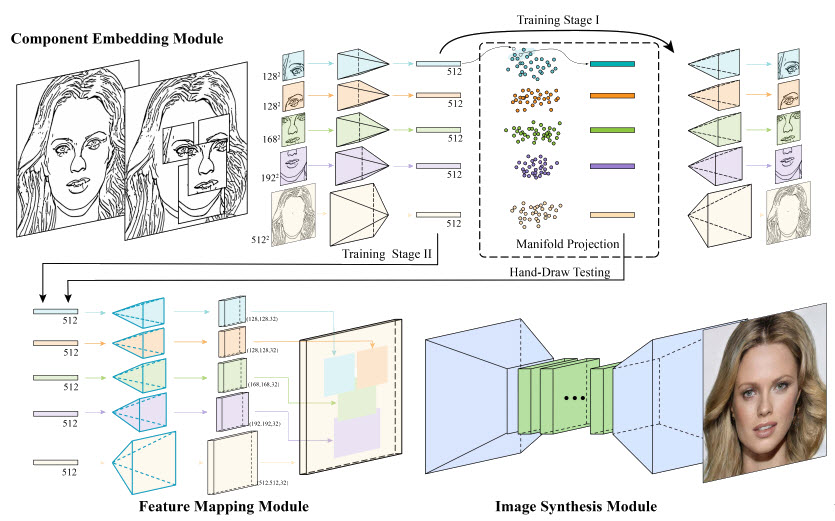
There are three main modules in the DeepFaceDrawing system: component embedding (CE), feature mapping (FM), and image synthesis (IS). The CE module forms the first sub-network and works on an auto-encoder architecture that helps in reconstructing the input. The second sub-network consists of two modules: feature mapping and image synthesis. In the experiment, a rough face sketch is the input and the output is a realistic image based on the face sketch data. The CE module detects five key face components from the sketch: left-eye, right-eye, nose, mouth, and rest of the face. The module turns component sketches into semantically meaningful feature vectors. Then, FM module turns the component feature vectors into the corresponding feature maps. For each feature map, FM has 32 channels. In addition to the improving information flow, these 32 channels help fuse individual face components to create higher quality synthesis results. The researchers have used a fixed depth order (i.e., “left/right eyes” > “nose” > “mouth” > “remainder”) to merge the feature maps. The feature maps of individual face components are then combined according to the face structure and finally passed to IS module for a realistic face image synthesis.
https://www.youtube.com/watch?v=HSunooUTwKs&ab
A user can experience the application interface from the Geometry Learning website. The shadow-guided sketching interface helps users with little training in drawing. It shows a blurry shadow when the canvas is empty, which gets updated with every new input stroke. The corresponding synthesized image is visible in the window on the right side. However, users with good drawing skills can make use of sliders provided for each face component type to control the blending weights between a sketched component and its refined version after manifold projection. Fine-tuning of the blending weights leads to a result better reflecting the input sketch more faithfully.
While in shadow-guided sketching interface, I tried to draw sketch of physicist Albert Einstein. I was curious to see what the outcome would be. But I found that the experiment depends on the CelebAMask-HQ dataset. It is a large-scale face image dataset that has 30,000 high-resolution face images selected from the CelebA dataset by following CelebA-HQ. Each image has segmentation mask of facial attributes corresponding to CelebA. Presently, the experiment focuses on front faces only, without accessories like glasses, face masks, etc. Researcher Hongbo Fu says that the experiment can work with various phenotypes like different ethnicities and less common traits like snub nose. It really depends on the training data. The output images shown in the experiment are all of White people. Were brown- or dark-skinned faces excluded from the training data? Fu replies that the current training dataset (CelebAMask-HQ) does not have a lot of dark-skinned faces. Also their current algorithm does not have any control over skin color. According to the dataset agreement on GitHub, the CelebAMask-HQ dataset is available for non-commercial research purposes only. So, in the commercial version of DeepFaceDrawing, we might expect to see an extensive database with no limit on the factors mentioned above.
The existing sketch-to-image synthesis methods require high-quality sketches or smoothed edge maps to produce realistic images. Their poor ability to handle hand-drawn sketches limits the usage of the application. These methods tend to use input sketches as hard constraints, limiting the ability to handle data imperfections. Therefore, the output image is somewhat distorted.
The methodology described in this research paper follows a local-to-global approach, which breaks the face sketch into components, the manifold projection retrieves the closest component sample in each component-level feature space, mapping the refined feature vectors to the feature maps for spatial combination, and finally translating the combined feature maps to realistic images.
What do we think?
As we know, the input here is black and white sketches. If the application provides more control over color and texture of the input, we might have desired facial attributes in the output image, e.g., hair color, skin color, makeup, etc. Adding random noise to input can increase the diversity of the results. The group says future projects also look at the ability to synthesize objects of other categories. I would love to draw sketches of automobiles, furniture, jewelry, etc.
A technology like this might one day become available as a consumer or commercial product that would help in catching criminals or creating realistic images of imaginary characters for films or print media. The students with minimal sketching skills can learn to design things and wouldn’t it be wonderful to be able to generate life-like realistic images from a rough sketch, whenever needed.
This is fantastic work and will likely show up in paint and drawing programs very soon. In the old days, and maybe still today, there was an effort to digitize old drawings. Due to creases in the paper, stains, and scratches, the task was from difficult to impossible without a lot of human intervention. This AI-based system could overcome a lot of those obstacles and be a useful tool for the archival needs of many organizations and institutions.




